|
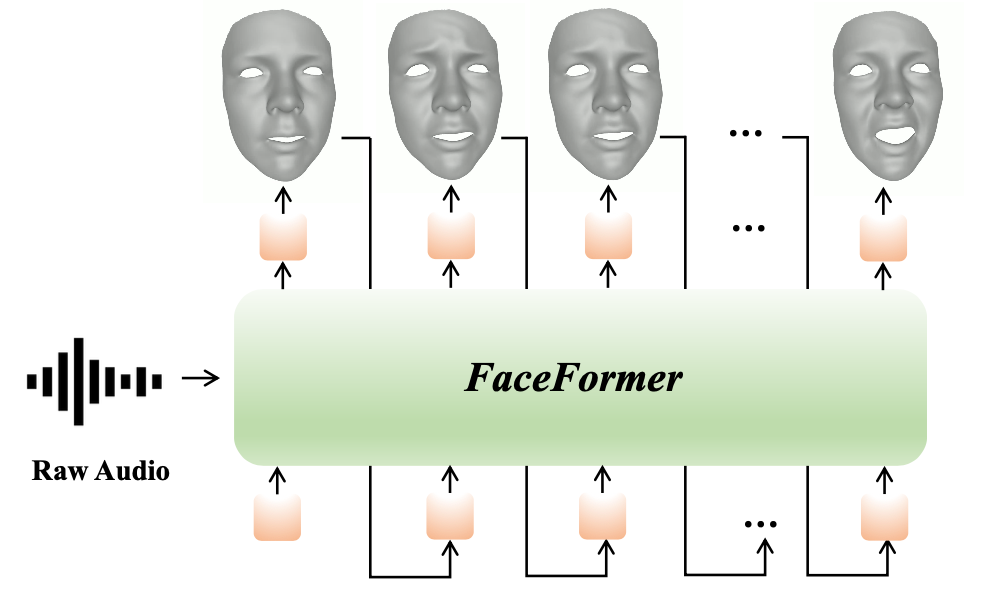
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased crossmodal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts.
|